
上一篇文章中,我們大概知道了 Pre-Retrieval 的方向,也嘗試的實作以後,接下我們將要進行Post-Retrieval 。
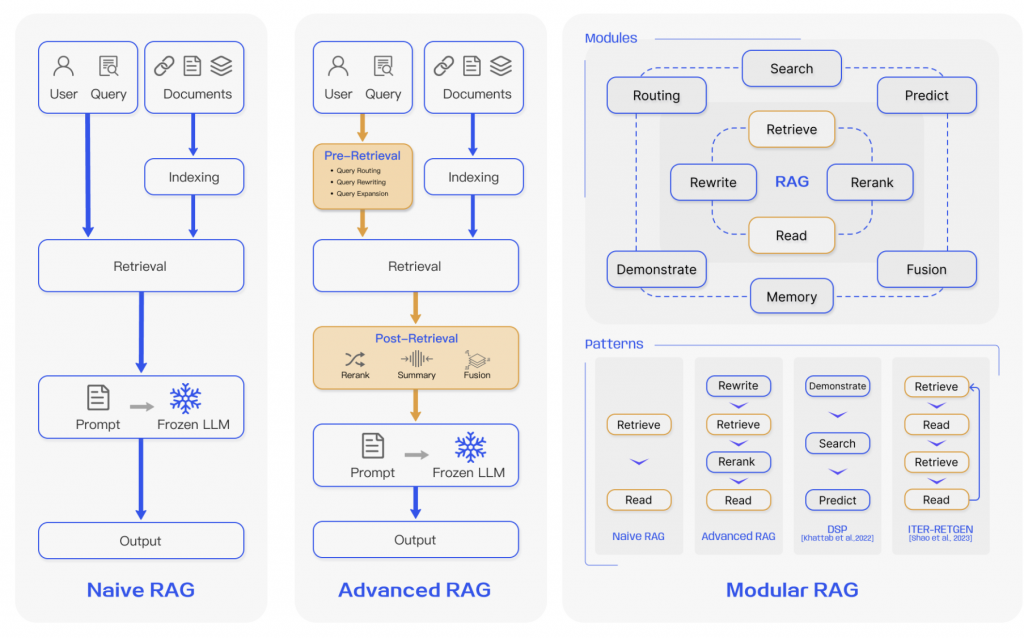
下面是這篇原始論文中的段落
Retrieval-Augmented Generation for Large Language Models: A Survey
Post-Retrieval Process. Once relevant context is retrieved, it’s crucial to integrate it effectively with the query. The main methods in post-retrieval process include rerank chunks and context compressing. Re-ranking the retrieved information to relocate the most relevant content to the edges of the prompt is a key strategy. This concept has been implemented in frameworks such as LlamaIndex2 , LangChain3 , and HayStack [12]. Feeding all relevant documents directly into LLMs can lead to information overload, diluting the focus on key details with irrelevant content.To mitigate this, post-retrieval efforts concentrate on selecting the essential information, emphasizing critical sections, and shortening the context to be processed
Post-Retrieval 的核心目的是 :
在送給 Prompt 之前,先將 Retrive 出來的結果進行處理,讓產生出來的 Context 更有效果。
根據這篇 Retrieval-Augmented Generation for Large Language Models: A Survey 論文中,提到 Post-retrieval 的過程中,核心的優化手法有兩個也還是兩個 :
打分方式重新排序,把最 relevant 的放到最前面。首先來說一下要進行 Reranking,目前主要是有兩個方向 :
然後接下這個情境我想要混合的情境來進行,主要是這兩個方向 :
而且Context Compressing這個部份,還在研究中。
🤔 字幕情境的 Rule Reranking 原理說明
這裡會以時間為主的 Rule 為主的 Reranking 方向,因為適合用於
字幕這種情境。
它整個原理是這樣。我們在第一次 Retrive 結束後,我們拿到的 Chunk 是被打散的,例如如下 :
1. [02:30] "RAG 可以減少幻覺問題..." (score: 0.89)
2. [05:12] "透過檢索真實文檔來避免幻覺..." (score: 0.85)
3. [00:18] "為什麼要用 RAG 呢..." (score: 0.82)
4. [08:45] "幻覺是 LLM 的常見問題..." (score: 0.80)
5. [02:15] "RAG 的優點包括..." (score: 0.78)
但字幕類型有個特性 :
時間越接近的,就有可能在講越相同的事
所以沒有注意到上面範例的 1 與 5 這兩個 chunk 它們事實上在說相同的事情,對吧,所以這裡就是要將這種的合在一起,然後再進行排序,概念碼如下。
// Step 1: 先檢索 top-10
const top10 = vectorSearch(query, k=10);
// Step 2: 時間聚類分析
const clusters = findTemporalClusters(top10);
/*
結果:
Cluster 1: [02:15 - 02:47] // 3 個片段,總分 2.52
- [02:15] score: 0.78
- [02:30] score: 0.89
- [02:39] score: 0.85
Cluster 2: [05:12 - 05:20] // 1 個片段,總分 0.85
- [05:12] score: 0.85
Cluster 3: [08:40 - 08:55] // 2 個片段,總分 1.50
- [08:45] score: 0.80
- [08:50] score: 0.70
*/
⚠️ 程式碼重點說明
然後這裡說明一下程式碼的整個核心邏輯,首先是最下面這一段,他就是會將我們拿到第一次 retrieve 後拿到的 documents,然後根據上面的規則,組合 cluster。
for (const doc of documents) {
const gap = doc.start_ms - currentCluster.end_ms;
if (gap <= maxGap) {
// 時間接近,合併到當前聚類
currentCluster.docs.push(doc);
currentCluster.end_ms = doc.end_ms;
} else {
// 間隔太大,開始新聚類
if (currentCluster.docs.length >= minClusterSize) {
clusters.push(currentCluster);
}
currentCluster = createNewCluster(doc);
}
}
然後有個重要參數 maxGap 決定了時間合併的範圍。例如 30秒 意味著:
片段A: [02:10-02:20]
片段B: [02:25-02:35] ← 間隔 5 秒,合併 ✓
片段C: [03:10-03:20] ← 間隔 35 秒,獨立 ✗
參數 minClusterSize 代表每個 cluster 是否存活的門檻,這裡是設 2,意味著,至少要有兩個差不多時間區間的 chunk,才能組成一個 cluster,然後它就說掰了。
接下來是計算 cluster 總合分數的地方,就是那個 cluster 比較有參考價值,主要是用 2 個面向來評份 :
// 計算 Cluster 的綜合分數
private finalizeCluster(cluster: Cluster): void {
const avgRelevance = cluster.totalScore / cluster.docs.length;
const durationSeconds = (cluster.endMs - cluster.startMs) / 1000;
const density = cluster.docs.length / Math.max(durationSeconds, 1);
const densityBonus = Math.log(1 + density) * this.densityWeight;
cluster.compositeScore = avgRelevance + densityBonus;
cluster.density = density;
}
🤔 LLM Reranking 原理說明
這裡我們會根據優化 1 回傳的結果,再透過 Voyage 這裡 Reranking Model 來進行一次 reranke,主要的目的在於 :
Reranking Model 會將
你的問題,與我們透過優化 1 得到的 Cluster ( Chunk 集 ),再次進行一次評分排序
還蠻簡單的,就是叫 voyage 的 api。
export interface VoyageRerankResponse {
object: string;
data: {
relevance_score: number;
index: number;
}[];
model: string;
usage: {
total_tokens: number;
};
}
export interface VoyageRerankResponse {
object: string;
data: {
relevance_score: number;
index: number;
}[];
model: string;
usage: {
total_tokens: number;
};
}
export class VoyageReranker {
private apiKey: string;
private model: string;
private baseURL: string;
constructor(apiKey: string, model: string = "rerank-2") {
this.apiKey = apiKey;
this.model = model;
this.baseURL = "https://api.voyageai.com/v1";
}
async rerank(
query: string,
documents: RankedDocument[],
topK?: number
): Promise<RankedDocument[]> {
try {
const response = await fetch(`${this.baseURL}/rerank`, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${this.apiKey}`,
},
body: JSON.stringify({
query: query,
documents: documents.map((d) => d.pageContent),
model: this.model,
top_k: topK,
return_documents: false,
}),
});
if (!response.ok) {
throw new Error(`Voyage API 錯誤: ${response.statusText}`);
}
const result: VoyageRerankResponse = await response.json();
console.log("Voyage Reranking Response:", result);
const reranked = result.data.map((result) => ({
...documents[result.index],
rerank_score: result.relevance_score,
original_score: documents[result.index].score,
}));
return reranked;
} catch (error) {
console.error("[Voyage Reranking] 錯誤:", error);
return documents;
}
}
}
下面這個是 Voyage 的結果,它就是會將你給的每個 cluster 再一次進行評分。
Voyage Reranking Response: {
object: 'list',
data: [
{ relevance_score: 0.75390625, index: 0 },
{ relevance_score: 0.75390625, index: 9 },
{ relevance_score: 0.7421875, index: 8 },
{ relevance_score: 0.69921875, index: 1 },
{ relevance_score: 0.69140625, index: 2 },
{ relevance_score: 0.6796875, index: 4 },
{ relevance_score: 0.546875, index: 5 },
{ relevance_score: 0.5390625, index: 3 },
{ relevance_score: 0.5, index: 10 },
{ relevance_score: 0.5, index: 11 }
],
model: 'rerank-lite-1',
usage: { total_tokens: 1916 }
}
🤔 Rerank Model 如何選 ? 中文方面我是建議看 ihower 寫的這篇
真的得這裡學到很多東西
使用繁體中文評測各家 Reranker 模型的重排能力-ihower
整個流程就是如下,範例程式碼,流程事實上還算好理解 :
const query = async (message: string) => {
// ===== Stage 1: Query Expansion ( Pre-Retrieval ) =====
const queryVariants = await this.generateQueryVariants(
originalQuery,
this.config.numQueryVariants
);
const hypotheticalAnswer = await this.generateHypotheticalAnswer(
originalQuery
);
const searchQueries = [originalQuery, ...queryVariants, hypotheticalAnswer];
// ===== Stage 2: Vector Search =====
console.log(`\n--- Stage 2: Vector Search ---`);
const candidates = await this.vectorSearch(
searchQueries,
k * this.config.retrievalMultiplier
);
// ===== Stage 3: Temporal Cluster ( Post-Retrieval ) =====
const clustered = this.temporalReranker.rerank(candidates, k * 2);
// ===== Stage 4: Voyage Reranking ( Post-Retrieval ) =====
const contexts = await this.voyageReranker.rerank(originalQuery, clustered, k);
// ===== Stage 5: 將 Context 代到 Prompt 中生成答案 =====
const result = await model.invoke([
{
role: "system",
content: `
# Context: ${contexts
.map((c, i) => {
return `[${i + 1}] 時間: ${formatTime(
c.metadata.start_ms
)}-${formatTime(c.metadata.end_ms)} | 相關性: ${
c.rerank_score?.toFixed(3) || "N/A"
}
內容: ${c.pageContent}`;
})
.join("\n\n")}
# Instructions:
- 你只能根據 Context 回答相關的問題
- 說明答案的來源時間範圍(格式: "MM:SS~MM:SS")
- 限制在 500 個字以內
- 如果 Context 中沒有相關信息,誠實告知
`,
},
{ role: "user", content: message },
]);
};
這篇文章我們主要專注在研究 Post-Retrieval 的 Reranking 這個的技術,它目前在很多篇論文中都有提到他是效果很好的手法,然後真的研究下去後真的發現,好像這個不是一篇文章寫的完的東西,可以參考 ihower 的筆記,這一塊水真的有點深。
https://ihower.tw/notes/AI-Engineer/RAG/Reranking
這裡只能先針對我們這個情境來想一下比較適合的方案,之後有時間再來深入研究這塊東西。
